使用Vitis HLS实现和优化DethSepConv函数
1初版功能验证
1.0设计框图
+-----------------------------------+ | Input Data | +----------------+------------------+ | Data Split / Parallel Ops +----------------V------------------+ | Depthwise Convolution Layer | Pipelined / Parallel Execution using DSP +----------------+------------------+ | +----------------V------------------+ | Batch Normalization | +----------------+------------------+ | +----------------V------------------+ | Activation Function | +----------------+------------------+ | +----------------V------------------+ | SE Block (Optional) | +----------------+------------------+ | +----------------V------------------+ | Pointwise Convolution Layer | Pipelined / Parallel Execution using DSP +----------------+------------------+ | +----------------V------------------+ | Batch Normalization | +----------------+------------------+ | +----------------V------------------+ | Activation Function | +----------------+------------------+ | +----------------V------------------+ | Output Data | +-----------------------------------+
1.1源码
//Activation.h
#ifndef ACTIVATION_H
#define ACTIVATION_H
inline float hard_swich(float x) {
return x > 0 ? x : 0;
}
template<int CHANNELS>
void Activation(float input[CHANNELS][32][32],
float output[CHANNELS][32][32],
float(*activation_function)(float)) {
for(int ch = 0; ch < CHANNELS; ch++) {
for(int row = 0; row < 32; row++) {
for(int col = 0; col < 32; col++) {
output[ch][row][col] = activation_function(input[ch][row][col]);
}
}
}
}
#endif//BatchNormalization.h
#ifndef BATCHNORMALIZATION_H
#define BATCHNORMALIZATION_H
template<int CHANNELS>
void BatchNormalization(float input[CHANNELS][32][32],
float output[CHANNELS][32][32],
float mean[CHANNELS],
float variance[CHANNELS],
float gamma[CHANNELS],
float beta[CHANNELS],
float epsilon = 1e-5) {
for(int ch = 0; ch < CHANNELS; ch++) {
for(int row = 0; row < 32; row++) {
for(int col = 0; col < 32; col++) {
output[ch][row][col] = gamma[ch] * ((input[ch][row][col] - mean[ch]) / hls::sqrt(variance[ch] + epsilon)) + beta[ch];
}
}
}
}
#endif// Conv2D.h
#ifndef CONV2D_H
#define CONV2D_H
#include "ap_int.h"
#include "hls_stream.h"
#include "hls_math.h"
// 普通卷积运算
template<int INPUT_CHANNELS, int OUTPUT_CHANNELS, int KERNEL_SIZE, int STRIDE>
void Conv2D(float input[INPUT_CHANNELS][32][32],
float output[OUTPUT_CHANNELS][32][32],
float weights[OUTPUT_CHANNELS][INPUT_CHANNELS][KERNEL_SIZE][KERNEL_SIZE]) {
// 卷积运算实现
for(int out_ch = 0; out_ch < OUTPUT_CHANNELS; out_ch++) {
for(int row = 0; row < 32; row += STRIDE) {
for(int col = 0; col < 32; col += STRIDE) {
float acc = 0;
for(int in_ch = 0; in_ch < INPUT_CHANNELS; in_ch++) {
for(int k_row = 0; k_row < KERNEL_SIZE; k_row++) {
for(int k_col = 0; k_col < KERNEL_SIZE; k_col++) {
int in_row = row + k_row - KERNEL_SIZE/2;
int in_col = col + k_col - KERNEL_SIZE/2;
if (in_row >= 0 && in_row < 32 && in_col >= 0 && in_col < 32) {
acc += input[in_ch][in_row][in_col] * weights[out_ch][in_ch][k_row][k_col];
}
}
}
}
output[out_ch][row][col] = acc;
}
}
}
}
// 深度卷积运算
template<int CHANNELS, int KERNEL_SIZE, int STRIDE>
void DepthwiseConv2D(float input[CHANNELS][32][32],
float output[CHANNELS][32][32],
float weights[CHANNELS][1][KERNEL_SIZE][KERNEL_SIZE]) {
// 深度卷积运算实现
for(int ch = 0; ch < CHANNELS; ch++) {
for(int row = 0; row < 32; row += STRIDE) {
for(int col = 0; col < 32; col += STRIDE) {
float acc = 0;
for(int k_row = 0; k_row < KERNEL_SIZE; k_row++) {
for(int k_col = 0; k_col < KERNEL_SIZE; k_col++) {
int in_row = row + k_row - KERNEL_SIZE/2;
int in_col = col + k_col - KERNEL_SIZE/2;
if (in_row >= 0 && in_row < 32 && in_col >= 0 && in_col < 32) {
acc += input[ch][in_row][in_col] * weights[ch][0][k_row][k_col];
}
}
}
output[ch][row][col] = acc;
}
}
}
}
#endif// DethSepConv.h
#ifndef DETHSEPCONV_H
#define DETHSEPCONV_H
#include "Conv2D.h"
#include "BatchNormalization.h"
#include "Activation.h"
#include "SE_block.h"
template<int INPUT_CHANNELS, int OUTPUT_CHANNELS, int KERNEL_SIZE, int STRIDE>
void DethSepConv(float input[INPUT_CHANNELS][32][32],
float output[OUTPUT_CHANNELS][32][32],
float depthwise_weights[INPUT_CHANNELS][1][KERNEL_SIZE][KERNEL_SIZE],
float pointwise_weights[OUTPUT_CHANNELS][INPUT_CHANNELS][1][1],
float bn_mean1[INPUT_CHANNELS], float bn_var1[INPUT_CHANNELS],
float bn_gamma1[INPUT_CHANNELS], float bn_beta1[INPUT_CHANNELS],
float bn_mean2[OUTPUT_CHANNELS], float bn_var2[OUTPUT_CHANNELS],
float bn_gamma2[OUTPUT_CHANNELS], float bn_beta2[OUTPUT_CHANNELS],
bool use_se = false,
float se_fc1_weights[INPUT_CHANNELS/16][INPUT_CHANNELS] = nullptr,
float se_fc1_bias[INPUT_CHANNELS/16] = nullptr,
float se_fc2_weights[INPUT_CHANNELS][INPUT_CHANNELS/16] = nullptr,
float se_fc2_bias[INPUT_CHANNELS] = nullptr) {
#pragma HLS INTERFACE m_axi port = input offset = slave bundle = gmem
#pragma HLS INTERFACE m_axi port = output offset = slave bundle = gmem
#pragma HLS INTERFACE m_axi port = depthwise_weights offset = slave bundle = gmem
#pragma HLS INTERFACE m_axi port = pointwise_weights offset = slave bundle = gmem
#pragma HLS INTERFACE m_axi port = bn_mean1 offset = slave bundle = gmem
#pragma HLS INTERFACE m_axi port = bn_var1 offset = slave bundle = gmem
#pragma HLS INTERFACE m_axi port = bn_gamma1 offset = slave bundle = gmem
#pragma HLS INTERFACE m_axi port = bn_beta1 offset = slave bundle = gmem
#pragma HLS INTERFACE m_axi port = bn_mean2 offset = slave bundle = gmem
#pragma HLS INTERFACE m_axi port = bn_var2 offset = slave bundle = gmem
#pragma HLS INTERFACE m_axi port = bn_gamma2 offset = slave bundle = gmem
#pragma HLS INTERFACE m_axi port = bn_beta2 offset = slave bundle = gmem
#pragma HLS INTERFACE m_axi port = se_fc1_weights offset = slave bundle = gmem
#pragma HLS INTERFACE m_axi port = se_fc1_bias offset = slave bundle = gmem
#pragma HLS INTERFACE m_axi port = se_fc2_weights offset = slave bundle = gmem
#pragma HLS INTERFACE m_axi port = se_fc2_bias offset = slave bundle = gmem
#pragma HLS INTERFACE s_axilite port = use_se bundle = control
#pragma HLS INTERFACE s_axilite port = return bundle = control
float depthwise_out[INPUT_CHANNELS][32][32];
float bn1_out[INPUT_CHANNELS][32][32];
float activation1_out[INPUT_CHANNELS][32][32];
float se_out[INPUT_CHANNELS][32][32];
float pointwise_out[OUTPUT_CHANNELS][32][32];
float bn2_out[OUTPUT_CHANNELS][32][32];
DepthwiseConv2D<INPUT_CHANNELS, KERNEL_SIZE, STRIDE>(input, depthwise_out, depthwise_weights);
BatchNormalization<INPUT_CHANNELS>(depthwise_out, bn1_out, bn_mean1, bn_var1, bn_gamma1, bn_beta1);
Activation<INPUT_CHANNELS>(bn1_out, activation1_out, hard_swich);
if (use_se) {
SE_block<INPUT_CHANNELS>(activation1_out, se_out, se_fc1_weights, se_fc1_bias, se_fc2_weights, se_fc2_bias);
} else {
for (int ch = 0; ch < INPUT_CHANNELS; ch++) {
for (int row = 0; row < 32; row++) {
for (int col = 0; col < 32; col++) {
se_out[ch][row][col] = activation1_out[ch][row][col];
}
}
}
}
Conv2D<INPUT_CHANNELS, OUTPUT_CHANNELS, 1, 1>(se_out, pointwise_out, pointwise_weights);
BatchNormalization<OUTPUT_CHANNELS>(pointwise_out, bn2_out, bn_mean2, bn_var2, bn_gamma2, bn_beta2);
Activation<OUTPUT_CHANNELS>(bn2_out, output, hard_swich);
}
#endif//SE_block.h
#ifndef SE_BLOCK_H
#define SE_BLOCK_H
template<int CHANNELS>
void SE_block(float input[CHANNELS][32][32],
float output[CHANNELS][32][32],
float fc1_weights[CHANNELS/16][CHANNELS],
float fc1_bias[CHANNELS/16],
float fc2_weights[CHANNELS][CHANNELS/16],
float fc2_bias[CHANNELS]) {
float pooled[CHANNELS] = {0};
// 全局平均池化
for (int ch = 0; ch < CHANNELS; ch++) {
for (int row = 0; row < 32; row++) {
for (int col = 0; col < 32; col++) {
pooled[ch] += input[ch][row][col];
}
}
pooled[ch] /= 32 * 32;
}
float fc1_out[CHANNELS / 16] = {0};
// 第一个全连接层
for (int i = 0; i < CHANNELS / 16; i++) {
for (int j = 0; j < CHANNELS; j++) {
fc1_out[i] += pooled[j] * fc1_weights[i][j];
}
fc1_out[i] += fc1_bias[i];
fc1_out[i] = hard_swich(fc1_out[i]);
}
float fc2_out[CHANNELS] = {0};
// 第二个全连接层
for (int i = 0; i < CHANNELS; i++) {
for (int j = 0; j < CHANNELS / 16; j++) {
fc2_out[i] += fc1_out[j] * fc2_weights[i][j];
}
fc2_out[i] += fc2_bias[i];
fc2_out[i] = hard_swich(fc2_out[i]);
}
for (int ch = 0; ch < CHANNELS; ch++) {
for (int row = 0; row < 32; row++) {
for (int col = 0; col < 32; col++) {
output[ch][row][col] = input[ch][row][col] * fc2_out[ch];
}
}
}
}
#endif// top.cpp
#include "DethSepConv.h"
extern "C" {
void top_function(float input[32][32][32],
float output[64][32][32],
float depthwise_weights[32][1][3][3],
float pointwise_weights[64][32][1][1],
float bn_mean1[32],
float bn_var1[32],
float bn_gamma1[32],
float bn_beta1[32],
float bn_mean2[64],
float bn_var2[64],
float bn_gamma2[64],
float bn_beta2[64],
bool use_se,
float se_fc1_weights[2][32],
float se_fc1_bias[2],
float se_fc2_weights[32][2],
float se_fc2_bias[32]) {
#pragma HLS INTERFACE m_axi port = input offset = slave bundle = gmem
#pragma HLS INTERFACE m_axi port = output offset = slave bundle = gmem
#pragma HLS INTERFACE m_axi port = depthwise_weights offset = slave bundle = gmem
#pragma HLS INTERFACE m_axi port = pointwise_weights offset = slave bundle = gmem
#pragma HLS INTERFACE m_axi port = bn_mean1 offset = slave bundle = gmem
#pragma HLS INTERFACE m_axi port = bn_var1 offset = slave bundle = gmem
#pragma HLS INTERFACE m_axi port = bn_gamma1 offset = slave bundle = gmem
#pragma HLS INTERFACE m_axi port = bn_beta1 offset = slave bundle = gmem
#pragma HLS INTERFACE m_axi port = bn_mean2 offset = slave bundle = gmem
#pragma HLS INTERFACE m_axi port = bn_var2 offset = slave bundle = gmem
#pragma HLS INTERFACE m_axi port = bn_gamma2 offset = slave bundle = gmem
#pragma HLS INTERFACE m_axi port = bn_beta2 offset = slave bundle = gmem
#pragma HLS INTERFACE m_axi port = se_fc1_weights offset = slave bundle = gmem
#pragma HLS INTERFACE m_axi port = se_fc1_bias offset = slave bundle = gmem
#pragma HLS INTERFACE m_axi port = se_fc2_weights offset = slave bundle = gmem
#pragma HLS INTERFACE m_axi port = se_fc2_bias offset = slave bundle = gmem
#pragma HLS INTERFACE s_axilite port = use_se bundle = control
#pragma HLS INTERFACE s_axilite port = return bundle = control
DethSepConv<32, 64, 3, 1>(input, output,
depthwise_weights, pointwise_weights,
bn_mean1, bn_var1, bn_gamma1, bn_beta1,
bn_mean2, bn_var2, bn_gamma2, bn_beta2,
use_se,
se_fc1_weights, se_fc1_bias,
se_fc2_weights, se_fc2_bias);
}
}1.2仿真激励
// TestDethSepConv.cpp
#include <iostream>
#include <cstdio>
#include "DethSepConv.h"
void initialize_array(float* array, int size) {
for(int i = 0; i < size; i++) {
array[i] = static_cast<float>(rand()) / static_cast<float>(RAND_MAX) - 0.5; // [-0.5, 0.5] 范围内的随机值
}
}
int main() {
constexpr int INPUT_CHANNELS = 32; //改成32通道
constexpr int OUTPUT_CHANNELS = 64; //改成64通道
constexpr int KERNEL_SIZE = 3;
constexpr int STRIDE = 1;
float input[INPUT_CHANNELS][32][32];
float output[OUTPUT_CHANNELS][32][32];
float depthwise_weights[INPUT_CHANNELS][1][KERNEL_SIZE][KERNEL_SIZE];
float pointwise_weights[OUTPUT_CHANNELS][INPUT_CHANNELS][1][1];
float bn_mean1[INPUT_CHANNELS];
float bn_var1[INPUT_CHANNELS];
float bn_gamma1[INPUT_CHANNELS];
float bn_beta1[INPUT_CHANNELS];
float bn_mean2[OUTPUT_CHANNELS];
float bn_var2[OUTPUT_CHANNELS];
float bn_gamma2[OUTPUT_CHANNELS];
float bn_beta2[OUTPUT_CHANNELS];
float se_fc1_weights[INPUT_CHANNELS/16][INPUT_CHANNELS];
float se_fc1_bias[INPUT_CHANNELS/16];
float se_fc2_weights[INPUT_CHANNELS][INPUT_CHANNELS/16];
float se_fc2_bias[INPUT_CHANNELS];
// 初始化数组
initialize_array((float*)input, INPUT_CHANNELS * 32 * 32);
initialize_array((float*)depthwise_weights, INPUT_CHANNELS * 1 * KERNEL_SIZE * KERNEL_SIZE);
initialize_array((float*)pointwise_weights, OUTPUT_CHANNELS * INPUT_CHANNELS * 1 * 1);
initialize_array(bn_mean1, INPUT_CHANNELS);
initialize_array(bn_var1, INPUT_CHANNELS);
initialize_array(bn_gamma1, INPUT_CHANNELS);
initialize_array(bn_beta1, INPUT_CHANNELS);
initialize_array(bn_mean2, OUTPUT_CHANNELS);
initialize_array(bn_var2, OUTPUT_CHANNELS);
initialize_array(bn_gamma2, OUTPUT_CHANNELS);
initialize_array(bn_beta2, OUTPUT_CHANNELS);
initialize_array((float*)se_fc1_weights, (INPUT_CHANNELS/16) * INPUT_CHANNELS);
initialize_array(se_fc1_bias, (INPUT_CHANNELS/16));
initialize_array((float*)se_fc2_weights, INPUT_CHANNELS * (INPUT_CHANNELS/16));
initialize_array(se_fc2_bias, INPUT_CHANNELS);
// 调用DethSepConv功能
DethSepConv<INPUT_CHANNELS, OUTPUT_CHANNELS, KERNEL_SIZE, STRIDE>(
input, output,
depthwise_weights, pointwise_weights,
bn_mean1, bn_var1, bn_gamma1, bn_beta1,
bn_mean2, bn_var2, bn_gamma2, bn_beta2,
true, // 使用SE
se_fc1_weights, se_fc1_bias,
se_fc2_weights, se_fc2_bias);
// 打印输出以验证正确性 (简化版)
for (int ch = 0; ch < OUTPUT_CHANNELS; ch++) {
for (int row = 0; row < 32; row++) {
for (int col = 0; col < 32; col++) {
std::cout << "output[" << ch << "][" << row << "][" << col << "] = " << output[ch][row][col] << std::endl;
}
}
}
std::cout << "Test complete!" << std::endl;
return 0;
}1.3初版编译(未进行优化,仅验证功能)
1.4功能验证
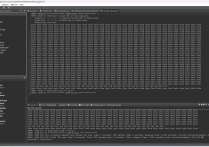
INFO: [SIM 2] *************** CSIM start *************** INFO: [SIM 4] CSIM will launch GCC as the compiler. Compiling ../../../../src/TestDethSepConv.cpp in debug mode Generating csim.exe output[0][0][0] = 0 output[0][0][1] = 0 output[0][0][2] = 0 output[0][0][3] = 0 output[0][0][4] = 0 ...... output[11][23][23] = 0.655102 output[11][23][24] = 0.65415 output[11][23][25] = 0.65152 ...... output[63][31][28] = 0 output[63][31][29] = 0 output[63][31][30] = 0 output[63][31][31] = 0 Test complete! INFO: [SIM 1] CSim done with 0 errors. INFO: [SIM 3] *************** CSIM finish ***************
功能验证通过!
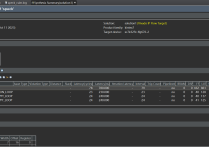
2实现优化
2.1初版优化
优化基于Vitis HLS的深度卷积代码的主要方向是并行化计算和优化内存访问。以下是详细的优化步骤和代码调整建议:
2.1.1. 在Activation模块中加入数据流指令 (Dataflow)
通过在 Activation 函数中使用 #pragma HLS pipeline 和 #pragma HLS unroll 指令来提高并行度,从而加速计算速度。
Activation.h
inline float hard_swich(float x) {
return x > 0 ? x : 0;}template<int CHANNELS>void Activation(float input[CHANNELS][32][32],
float output[CHANNELS][32][32],
float(*activation_function)(float)) {#pragma HLS inline
for(int ch = 0; ch < CHANNELS; ch++) {#pragma HLS unroll
for(int row = 0; row < 32; row++) {#pragma HLS pipeline
for(int col = 0; col < 32; col++) {
output[ch][row][col] = activation_function(input[ch][row][col]);
}
}
}}2.1.2. 在BatchNormalization模块中优化管道和循环级展开
同样的,我们可以对 BatchNormalization 函数进行类似的优化。
BatchNormalization.h
template<int CHANNELS>void BatchNormalization(float input[CHANNELS][32][32],
float output[CHANNELS][32][32],
float mean[CHANNELS],
float variance[CHANNELS],
float gamma[CHANNELS],
float beta[CHANNELS],
float epsilon = 1e-5) {#pragma HLS inline
for(int ch = 0; ch < CHANNELS; ch++) {#pragma HLS unroll
for(int row = 0; row < 32; row++) {#pragma HLS pipeline
for(int col = 0; col < 32; col++) {
output[ch][row][col] = gamma[ch] * ((input[ch][row][col] - mean[ch]) / hls::sqrt(variance[ch] + epsilon)) + beta[ch];
}
}
}}2.1.3. 在Conv2D和DepthwiseConv2D模块中使用管道、展开和数据流指令
对于 Conv2D 和 DepthwiseConv2D 函数,重点优化内层的卷积计算部分。
Conv2D.h
template<int INPUT_CHANNELS, int OUTPUT_CHANNELS, int KERNEL_SIZE, int STRIDE>void Conv2D(float input[INPUT_CHANNELS][32][32],
float output[OUTPUT_CHANNELS][32][32],
float weights[OUTPUT_CHANNELS][INPUT_CHANNELS][KERNEL_SIZE][KERNEL_SIZE]) {#pragma HLS inline#pragma HLS dataflow
for(int out_ch = 0; out_ch < OUTPUT_CHANNELS; out_ch++) {#pragma HLS unroll
for(int row = 0; row < 32; row += STRIDE) {#pragma HLS pipeline
for(int col = 0; col < 32; col += STRIDE) {
float acc = 0;
for(int in_ch = 0; in_ch < INPUT_CHANNELS; in_ch++) {#pragma HLS unroll
for(int k_row = 0; k_row < KERNEL_SIZE; k_row++) {#pragma HLS unroll
for(int k_col = 0; k_col < KERNEL_SIZE; k_col++) {
int in_row = row + k_row - KERNEL_SIZE/2;
int in_col = col + k_col - KERNEL_SIZE/2;
if (in_row >= 0 && in_row < 32 && in_col >= 0 && in_col < 32) {
acc += input[in_ch][in_row][in_col] * weights[out_ch][in_ch][k_row][k_col];
}
}
}
}
output[out_ch][row][col] = acc;
}
}
}}template<int CHANNELS, int KERNEL_SIZE, int STRIDE>void DepthwiseConv2D(float input[CHANNELS][32][32],
float output[CHANNELS][32][32],
float weights[CHANNELS][1][KERNEL_SIZE][KERNEL_SIZE]) {#pragma HLS inline#pragma HLS dataflow
for(int ch = 0; ch < CHANNELS; ch++) {#pragma HLS unroll
for(int row = 0; row < 32; row += STRIDE) {#pragma HLS pipeline
for(int col = 0; col < 32; col += STRIDE) {
float acc = 0;
for(int k_row = 0; k_row < KERNEL_SIZE; k_row++) {#pragma HLS unroll
for(int k_col = 0; k_col < KERNEL_SIZE; k_col++) {
int in_row = row + k_row - KERNEL_SIZE / 2;
int in_col = col + k_col - KERNEL_SIZE / 2;
if (in_row >= 0 && in_row < 32 && in_col >= 0 && in_col < 32) {
acc += input[ch][in_row][in_col] * weights[ch][0][k_row][k_col];
}
}
}
output[ch][row][col] = acc;
}
}
}}2.1.4. 在DethSepConv模块中使用数据流指令
将 DethSepConv 中不同层之间的数据流化。
DethSepConv.h
template<int INPUT_CHANNELS, int OUTPUT_CHANNELS, int KERNEL_SIZE, int STRIDE>void DethSepConv(float input[INPUT_CHANNELS][32][32],
float output[OUTPUT_CHANNELS][32][32],
float depthwise_weights[INPUT_CHANNELS][1][KERNEL_SIZE][KERNEL_SIZE],
float pointwise_weights[OUTPUT_CHANNELS][INPUT_CHANNELS][1][1],
float bn_mean1[INPUT_CHANNELS], float bn_var1[INPUT_CHANNELS],
float bn_gamma1[INPUT_CHANNELS], float bn_beta1[INPUT_CHANNELS],
float bn_mean2[OUTPUT_CHANNELS], float bn_var2[OUTPUT_CHANNELS],
float bn_gamma2[OUTPUT_CHANNELS], float bn_beta2[OUTPUT_CHANNELS],
bool use_se = false,
float se_fc1_weights[INPUT_CHANNELS/16][INPUT_CHANNELS] = nullptr,
float se_fc1_bias[INPUT_CHANNELS/16] = nullptr,
float se_fc2_weights[INPUT_CHANNELS][INPUT_CHANNELS/16] = nullptr,
float se_fc2_bias[INPUT_CHANNELS] = nullptr) {#pragma HLS dataflow
float depthwise_out[INPUT_CHANNELS][32][32];
float bn1_out[INPUT_CHANNELS][32][32];
float activation1_out[INPUT_CHANNELS][32][32];
float se_out[INPUT_CHANNELS][32][32];
float pointwise_out[OUTPUT_CHANNELS][32][32];
float bn2_out[OUTPUT_CHANNELS][32][32];
DepthwiseConv2D<INPUT_CHANNELS, KERNEL_SIZE, STRIDE>(input, depthwise_out, depthwise_weights);
BatchNormalization<INPUT_CHANNELS>(depthwise_out, bn1_out, bn_mean1, bn_var1, bn_gamma1, bn_beta1);
Activation<INPUT_CHANNELS>(bn1_out, activation1_out, hard_swich);
if (use_se) {
SE_block<INPUT_CHANNELS>(activation1_out, se_out, se_fc1_weights, se_fc1_bias, se_fc2_weights, se_fc2_bias);
} else {
for (int ch = 0; ch < INPUT_CHANNELS; ch++) {#pragma HLS unroll
for (int row = 0; row < 32; row++) {#pragma HLS pipeline
for (int col = 0; col < 32; col++) {
se_out[ch][row][col] = activation1_out[ch][row][col];
}
}
}
}
Conv2D<INPUT_CHANNELS, OUTPUT_CHANNELS, 1, 1>(se_out, pointwise_out, pointwise_weights);
BatchNormalization<OUTPUT_CHANNELS>(pointwise_out, bn2_out, bn_mean2, bn_var2, bn_gamma2, bn_beta2);
Activation<OUTPUT_CHANNELS>(bn2_out, output, hard_swich);}2.1.5. 在SE_block模块中使用指令
为SE_block函数添加管道和展开指令。
template<int CHANNELS>
void SE_block(float input[CHANNELS][32][32],
float output[CHANNELS][32][32],
float fc1_weights[CHANNELS/16][CHANNELS],
float fc1_bias[CHANNELS/16],
float fc2_weights[CHANNELS][CHANNELS/16],
float fc2_bias[CHANNELS]) {
float pooled[CHANNELS] = {0};
// 全局平均池化
for (int ch = 0; ch < CHANNELS; ch++) {
#pragma HLS unroll
for (int row = 0; row < 32; row++) {
#pragma HLS pipeline
for (int col = 0; col < 32; col++) {
pooled[ch] += input[ch][row][col];
}
}
pooled[ch] /= 32 * 32;
}
float fc1_out[CHANNELS / 16] = {0};
// 第一个全连接层
for (int i = 0; i < CHANNELS / 16; i++) {
#pragma HLS unroll
for (int j = 0; j < CHANNELS; j++) {
#pragma HLS pipeline
fc1_out[i] += pooled[j] * fc1_weights[i][j];
}
fc1_out[i] += fc1_bias[i];
fc1_out[i] = hard_swich(fc1_out[i]);
}
float fc2_out[CHANNELS] = {0};
// 第二个全连接层
for (int i = 0; i < CHANNELS; i++) {
#pragma HLS unroll
for (int j = 0; j < CHANNELS / 16; j++) {
#pragma HLS pipeline
fc2_out[i] += fc1_out[j] * fc2_weights[i][j];
}
fc2_out[i] += fc2_bias[i];
fc2_out[i] = hard_swich(fc2_out[i]);
}
for (int ch = 0; ch < CHANNELS; ch++) {
#pragma HLS unroll
for (int row = 0; row < 32; row++) {
#pragma HLS pipeline
for (int col = 0; col < 32; col++) {
output[ch][row][col] = input[ch][row][col] * fc2_out[ch];
}
}
}
}2.1.6. 在top_function中应用这些优化
我们可确保在 top_function 中使用了优化的子模块。
top.cpp
extern "C" {void top_function(float input[32][32][32],
float output[64][32][32],
float depthwise_weights[32][1][3][3],
float pointwise_weights[64][32][1][1],
float bn_mean1[32],
float bn_var1[32],
float bn_gamma1[32],
float bn_beta1[32],
float bn_mean2[64],
float bn_var2[64],
float bn_gamma2[64],
float bn_beta2[64],
bool use_se,
float se_fc1_weights[2][32],
float se_fc1_bias[2],
float se_fc2_weights[32][2],
float se_fc2_bias[32]) {#pragma HLS INTERFACE m_axi port = input offset = slave bundle = gmem#pragma HLS INTERFACE m_axi port = output offset = slave bundle = gmem#pragma HLS INTERFACE m_axi port = depthwise_weights offset = slave bundle = gmem#pragma HLS INTERFACE m_axi port = pointwise_weights offset = slave bundle = gmem#pragma HLS INTERFACE m_axi port = bn_mean1 offset = slave bundle = gmem#pragma HLS INTERFACE m_axi port = bn_var1 offset = slave bundle = gmem#pragma HLS INTERFACE m_axi port = bn_gamma1 offset = slave bundle = gmem#pragma HLS INTERFACE m_axi port = bn_beta1 offset = slave bundle = gmem#pragma HLS INTERFACE m_axi port = bn_mean2 offset = slave bundle = gmem#pragma HLS INTERFACE m_axi port = bn_var2 offset = slave bundle = gmem#pragma HLS INTERFACE m_axi port = bn_gamma2 offset = slave bundle = gmem#pragma HLS INTERFACE m_axi port = bn_beta2 offset = slave bundle = gmem#pragma HLS INTERFACE m_axi port = se_fc1_weights offset = slave bundle = gmem#pragma HLS INTERFACE m_axi port = se_fc1_bias offset = slave bundle = gmem#pragma HLS INTERFACE m_axi port = se_fc2_weights offset = slave bundle = gmem#pragma HLS INTERFACE m_axi port = se_fc2_bias offset = slave bundle = gmem#pragma HLS INTERFACE s_axilite port = use_se bundle = control#pragma HLS INTERFACE s_axilite port = return bundle = control#pragma HLS dataflow
DethSepConv<32, 64, 3, 1>(input, output,
depthwise_weights, pointwise_weights,
bn_mean1, bn_var1, bn_gamma1, bn_beta1,
bn_mean2, bn_var2, bn_gamma2, bn_beta2,
use_se,
se_fc1_weights, se_fc1_bias,
se_fc2_weights, se_fc2_bias);}}通过这些修改,我们可以显著提高这段基于Vitis HLS的深度卷积代码的执行速度。在每一个函数中使用 #pragma HLS pipeline 来提升并行度,通过 #pragma HLS unroll 指令减少循环开销,并且在需要数据流的地方使用 #pragma HLS dataflow 来优化模块间的数据传输。这样可以确保程序在FPGA上的高效执行。